



최근 1~2년 사이 데이터와 관련된 업종에서 많이 언급된 단어중 하나가 머신러닝(Machine learning, 기계학습)이다.
보다 정확하게는 머신러닝에 대한 관심이 최근에 들어 증가한 것이 아니라 머신러닝 기술을 활용할 수 있는 기회가 확대된 것과 관련이 있다. 4차 산업혁명 시대로 진입하면서 방대한 디지털 데이터가 더 많이 쌓이게 되었고,이러한 빅데이터의 관리와 처리,그리고 분석에 대한 관심이 고조되었다. 사람을 대신하여 기계가 학습을 한다는 것에 대하여 초기에는 의심과 호기심이 공존하는 긴장이 있었지만 알파고의 등장으로 기계가 세상을 지배할지도 모른다는 영화 같은 공포심을 불러일으키기도 했다. 그런데 진짜 고민은 이러한 기술을 누가,어떻게 사용할 것인가의 문제였다. 실제 실무자들 사이에서는 머신러닝 기술을 학습할 기회가 많지않았고 비전공자들에게는 접근 하기조차 어려운 분야이기 때문이다. 머신러닝 전문가나 기술자를 ‘모시는’ 것도 쉽지 않고,인재를 양성하기까지는 많은 시간과 비용이 든다. 이러한 고민을 해결하기 위해 등장한 것이 AutoML(Automated Machine Learrdng)이다.
대표적인 AutoML 제품들
AWS의 SageMaker는 201 7년 11월에 출시된 클라우드 머신러닝 플랫폼으로 데이터 전문가뿐만 아니라 개발자도 기계학습을 쉽게 이용하는 컨셉으로 서비스를 제공하고 있다. SageMaker의 장점은 머신러닝에 대한 기초적이고 일반적인 지식들을 함께 제공한다는 점이다. SageMaker 제품을 꼭쓰지않더라도 클라우드 기반 머신러닝에 대하여 쉽게 이해할 수 있다. 두 번째 장점은 엔드 투 엔드 통합 개발환경(IDE=lntegrated Development Environment)0| 가능하도록 서비스를 제공한다는 점이다.
사실, 머신러닝을 활용하기 위해서는 여러 단계가 필수적인데 각 단계들을 통합하여 관리도 할 수 있고 개발자 간 공유가 가능한 온라인 콜라보레이션 서비스도 있다. 반면,단점은 이러한 서비스가 개발자들을 위한 것으로 좀 더 치우쳐져 있어 코드에 대한 지식이 없는 일반인이나 데이터 분석가 들에게는 진입 장벽이 높은 편이다.
Google은 2018년 AutoML Vision을 처음 공개한 이후 현재 총 5개의 AutoML 제품을 서비스로 제공하고 있다. Google은 개발자나 데이터전문가뿐만 아니라 전문지식이 없는 일반인들도 사용할 수 있는 AutoML 제품을 제공하려는 컨셉을 가지고 있다. 따라서 UI도 사용자 편의를 반영하여 보기 쉽게 만들어졌고, GoogleCloud Platform(GCP)의 다른 제품들과 쉽게 호환되며,프로그래밍 언어를 이용한 코드사용 없이 클릭만으로 기계학습을 활용할 수 있다는 장점이 있다(물론, 개발자 환경도 제공하고 있다). 이렇게 구글의 머신러닝 제품은 쉽게 접근 가능한 반면,AWS에서처럼 정보나 자료를 제공하지 않아 활용방법에 대하여 따로 습득해야 한다 는 단점이 있다.
앞서 설명한 두 제품뿐만 아니라 대부분의 AutoML 제품들이 클라우드 환경을 기반으로 하므로 계정이나 프로젝트 생성은 필수이다. SageMaker는 무료버전과 유료버전이 있으며, 구글의 AutoML Tables는 유료이다. 더불어,클라우드 내 데이터베이스나 가상머신 (VM) 등을 이용할 경우 비용이 추가로 발생한다. 만약 비용을 미리 고려하지 않고 머신러닝을 활용하기 위한 전체 프로세스를 설계할 경우 계획보다 많은 비용을 지출해야 할지도 모른다. 그리고 AutoML 제품을 활용하기 위해서는 준비해야 할 기본적인 사항들이 있다. 이준비작업 없이도 AutoML은 이용 가능하지만 만족 할 만한 결과를 기대하기는 어렵다.
사실, 머신러닝을 활용하기 위해서는 여러 단계가 필수적인데 각 단계들을 통합하여 관리도 할 수 있고 개발자 간 공유가 가능한 온라인 콜라보레이션 서비스도 있다. 반면,단점은 이러한 서비스가 개발자들을 위한 것으로 좀 더 치우쳐져 있어 코드에 대한 지식이 없는 일반인이나 데이터 분석가 들에게는 진입 장벽이 높은 편이다.
Google은 2018년 AutoML Vision을 처음 공개한 이후 현재 총 5개의 AutoML 제품을 서비스로 제공하고 있다. Google은 개발자나 데이터전문가뿐만 아니라 전문지식이 없는 일반인들도 사용할 수 있는 AutoML 제품을 제공하려는 컨셉을 가지고 있다. 따라서 UI도 사용자 편의를 반영하여 보기 쉽게 만들어졌고, GoogleCloud Platform(GCP)의 다른 제품들과 쉽게 호환되며,프로그래밍 언어를 이용한 코드사용 없이 클릭만으로 기계학습을 활용할 수 있다는 장점이 있다(물론, 개발자 환경도 제공하고 있다). 이렇게 구글의 머신러닝 제품은 쉽게 접근 가능한 반면,AWS에서처럼 정보나 자료를 제공하지 않아 활용방법에 대하여 따로 습득해야 한다 는 단점이 있다.
앞서 설명한 두 제품뿐만 아니라 대부분의 AutoML 제품들이 클라우드 환경을 기반으로 하므로 계정이나 프로젝트 생성은 필수이다. SageMaker는 무료버전과 유료버전이 있으며, 구글의 AutoML Tables는 유료이다. 더불어,클라우드 내 데이터베이스나 가상머신 (VM) 등을 이용할 경우 비용이 추가로 발생한다. 만약 비용을 미리 고려하지 않고 머신러닝을 활용하기 위한 전체 프로세스를 설계할 경우 계획보다 많은 비용을 지출해야 할지도 모른다. 그리고 AutoML 제품을 활용하기 위해서는 준비해야 할 기본적인 사항들이 있다. 이준비작업 없이도 AutoML은 이용 가능하지만 만족 할 만한 결과를 기대하기는 어렵다.
AutoML을 사용하기 위한 준비작업
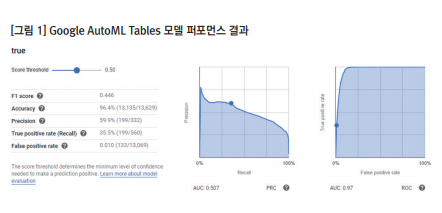
필자는 구글의 AutoML Tables가 2019년 4월 런칭되기 이전에 베타버전을 사용할 수 있는 기회가 있었다. 필자의 회사가 머신러닝을 활용한 캠페인 프로젝트를 구글과 진행중이어서 데이터 준비와 모델링에 참여를 했다. 결론적으로 구글의 AutoML Tables는 상당히 좋은 성능을 가진 제품이었다. 그도 그럴 것이 AutoML Tables는 딥러닝 기반 알고리즘이 내장되어 있어 크고 무거운 데이터까지 처리가능하다. 그리고 제품 런칭 이전에 많은 데이터로 테스트하고 다른 제품들과 비교한 자료를 공유 받아 제품 성능에 대한 우려는 크게 없었다. 문제는 데이터였다. 프로젝트의 목표는 웹사이트에 방문한 유저들의 전환 값에 대한 스코어링(spring) 즉,전환할 가능성을 확률로 계산하는 것이었는데 정확한 스코어링을 위해서는 새로운 feature를 만드는 작업이 필요했다. AutoML을 바로 쓸 수 없 는 이유는 바로 모델링을 위한 데이터가 준비되어야 한다는 점이다.
머신러닝 뿐만 아니라 데이터 분석에 앞서 데이터 정제 및 변수 작업은 필수적이다. 구체적인 분석 방법이나 적용할 알고리즘을 설계에 미리 포함하면 결과값에서 이상치를 발견되더라도 바로잡기가 어렵지 않다. 그러나 AutoML 제품들은 모델 퍼포먼스에 대한 정보가 상당히 구체적인 반면에,적용된 알고리즘 정보는 제공하지 않아서 최적화를 하기 어렵다. 따라서 데이터 준비 과정에서부터 충분한 데이터 탐색이 필요 하고 주요 feature들과 목표 값에 대한 기술통계량을 확인하는 등 준비작업이 요구된다.
머신러닝 뿐만 아니라 데이터 분석에 앞서 데이터 정제 및 변수 작업은 필수적이다. 구체적인 분석 방법이나 적용할 알고리즘을 설계에 미리 포함하면 결과값에서 이상치를 발견되더라도 바로잡기가 어렵지 않다. 그러나 AutoML 제품들은 모델 퍼포먼스에 대한 정보가 상당히 구체적인 반면에,적용된 알고리즘 정보는 제공하지 않아서 최적화를 하기 어렵다. 따라서 데이터 준비 과정에서부터 충분한 데이터 탐색이 필요 하고 주요 feature들과 목표 값에 대한 기술통계량을 확인하는 등 준비작업이 요구된다.
데이터세트 구성
데이터의 특성에 따라 AutoML에서 바로 사용할 수 있고,유저기반 데이터로 다시 만들거나 feature의 카테고리 값들을 one-hot encoding해야 할 수도 있다. 필자가 수행한 프로젝트 데이터는 웹사이트 트래픽 데이터로 유저 한 명이 여러 개의행데이터(row)를 가지고 있다. 때문에 유저기반 데이터로 변형이 필수였고, 리마케팅과 타깃팅을 위한 새로운 feature를 만드는 작업도 요구되었다[그림 2].
AutoML에서 사용할 데이터를 준비하는 작업은 아직까지 기계에 맡길 수 없는 질적 노동이므로 전문가의 손길이 필요하다. 데이터 준비작업은 비용절감을 위해 내부 인프라를 활용하는 것이 좋지만 인프라가 갖춰져 있지 않다면 클라우드 비용에 대하여 미리 숙지하여 적절한 비용으로 활용하면 된다. 준비하는 데 걸리는 시간은 데이터의 크기와 복잡성,목표에 따라 많이 다르지만 평균적으로 한 달의 시간이 필요하다.
AutoML에서 사용할 데이터를 준비하는 작업은 아직까지 기계에 맡길 수 없는 질적 노동이므로 전문가의 손길이 필요하다. 데이터 준비작업은 비용절감을 위해 내부 인프라를 활용하는 것이 좋지만 인프라가 갖춰져 있지 않다면 클라우드 비용에 대하여 미리 숙지하여 적절한 비용으로 활용하면 된다. 준비하는 데 걸리는 시간은 데이터의 크기와 복잡성,목표에 따라 많이 다르지만 평균적으로 한 달의 시간이 필요하다.
모델최적화와 모델 배치
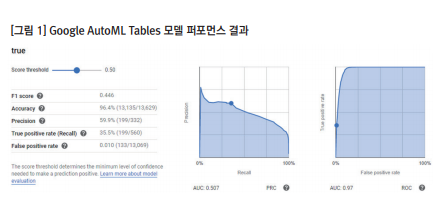
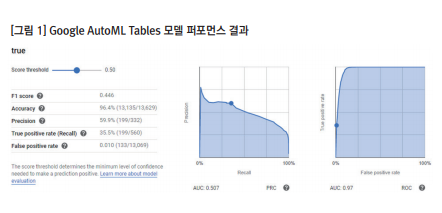
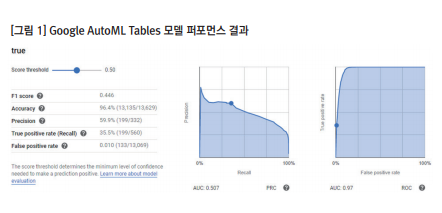
AutoML 모델링에는 최종적으로 46개의 feature가 사용되었다. 여러 feature들이 상관관계가 높거나 전환/비전환을 구분하는 특정 feature의 값이 상충되는 등 모델의 성능에 영향을 주는 요인들이 있다. 기계학습을 위해 알고리즘을 선택하여 직접 오류를 수정하는 등의 작업으로 최적화할 수 없으므로 feature의 구성을 조정하거나 새로 코딩을 하는 작업들을 반복해야 한다. 총 6번의 모델링 작업 후,가장 퍼포먼스가 좋은 모델을 캠페인에 적용하였다. AutoML의 결과로부터 유저들의 전환 가능성은 스코어가 반영된 등급으로 구분이 된다. 만들어진 모델은 구글 Ads와 같은 AD 서버에 배치를 하여 캠페인에 적용할 수 있다. 이 작업 역시 구글의 기술 인력이나 내부ICT 인프라를 활용해야 하는 전문적 분야이다. AutoML에서 구현한 모델을 광고에 적용하는 과정까지 자동화하기 위해서는 좀 저 많은 케이스가 데이터로 축적되어야 할 것이다.
결과적으로 AutoML을 활용한 리마케팅/타깃마케팅은 좋은 성과를 가져왔다. 그러나AutoML이 가지고 있는 좋은 성능이라는 매력과 적용된 알고리즘을 알 수 없어 모델 최적화가 어렵다는 한계가 공존한다. 때문에 전문지식이 없는 일반인들이 사용하기에는 무리가 있지만 개발자나 데이터 전문가들에게 유용한 제품인 것은 분명하다.
다만,AutoML을 잘 활용하기 위해서는 데이터에 대한 이해,준비,처리가 매우 중요하며,모델을 배치하고 적용할 수 있는 개발환 경에 대한 지식도 요구되므로 각 전문가들의 협업이 필수적이다. 유료 AutoML을 사용하기 전에 Auto-sklearn과 같은 오픈 소스나 Python, R 패키지에서 제공하는 머신러닝 라이브러리를 활용하여 테스트해 보는 것도 좋은 방법이다. 실제로 필자가 같은 데이터로 AutoML 유료 제품과 Auto-sklear 스 코 어 링 을 했 을 때 등 급 분 포 와 feature imp아tance의 결과가 조금 달랐다. 두 제품에 내장된 기본 알고리즘이 다르기 때문인데,이러한 결과의 차이는 캠페인의 성과로 이어질 수 있으므로 사용하려는 데이터,AutoML, 기본적인 알고리즘에 대한 충분한 이해가 선행되어야 할 것이다.
결과적으로 AutoML을 활용한 리마케팅/타깃마케팅은 좋은 성과를 가져왔다. 그러나AutoML이 가지고 있는 좋은 성능이라는 매력과 적용된 알고리즘을 알 수 없어 모델 최적화가 어렵다는 한계가 공존한다. 때문에 전문지식이 없는 일반인들이 사용하기에는 무리가 있지만 개발자나 데이터 전문가들에게 유용한 제품인 것은 분명하다.
다만,AutoML을 잘 활용하기 위해서는 데이터에 대한 이해,준비,처리가 매우 중요하며,모델을 배치하고 적용할 수 있는 개발환 경에 대한 지식도 요구되므로 각 전문가들의 협업이 필수적이다. 유료 AutoML을 사용하기 전에 Auto-sklearn과 같은 오픈 소스나 Python, R 패키지에서 제공하는 머신러닝 라이브러리를 활용하여 테스트해 보는 것도 좋은 방법이다. 실제로 필자가 같은 데이터로 AutoML 유료 제품과 Auto-sklear 스 코 어 링 을 했 을 때 등 급 분 포 와 feature imp아tance의 결과가 조금 달랐다. 두 제품에 내장된 기본 알고리즘이 다르기 때문인데,이러한 결과의 차이는 캠페인의 성과로 이어질 수 있으므로 사용하려는 데이터,AutoML, 기본적인 알고리즘에 대한 충분한 이해가 선행되어야 할 것이다.
AutoML, 어느 광고 캠페인에 적합한가
필자가 쓴 AutoML은 고객의 전환가능성을 중심으로 한 스코어링 방식이었다. 이방식은 적격고객을 찾아내는 타깃팅 방식 에 매우 유효한 방식이며,비즈니스 목표에 따라 머신러닝의 지도학습,비지도학습 기법을 선택적으로 사용할 수 있다. 여러 알고리즘이 들어가 있는 AutoML의 특성 때문에 매체데이터 혹은 그 이상의 복합 데이터만 있다면 e커머스 캠페인,금융 캠페인,앱캠페인 등 적격 고객을 적정한 가격 으로 모집하고자 하는 모든 타깃팅 및 리타깃팅 캠페인에 적용이 가능하다. 단,앞서 말한 바와 같이 데이터의 적극적 수집,목표의 정확한 설정 그리고 숙련된 데이터전문가의 리드와 실험설계는 필수적이다. AutoML의 목표는 시장 평균 퍼포먼스 이상의 퍼포먼스를 내는 대중화된 머신러닝 툴을 만드는 것이며, 타깃팅을 통해 R0I를 높이고자 하는 여러 광고캠페인에서도 기대 이상의 퍼포먼스를 낼 수 있다는 것이필자의 경험이었다.













































{kind=link}
{kind=link}
{kind=link}
{kind=link}